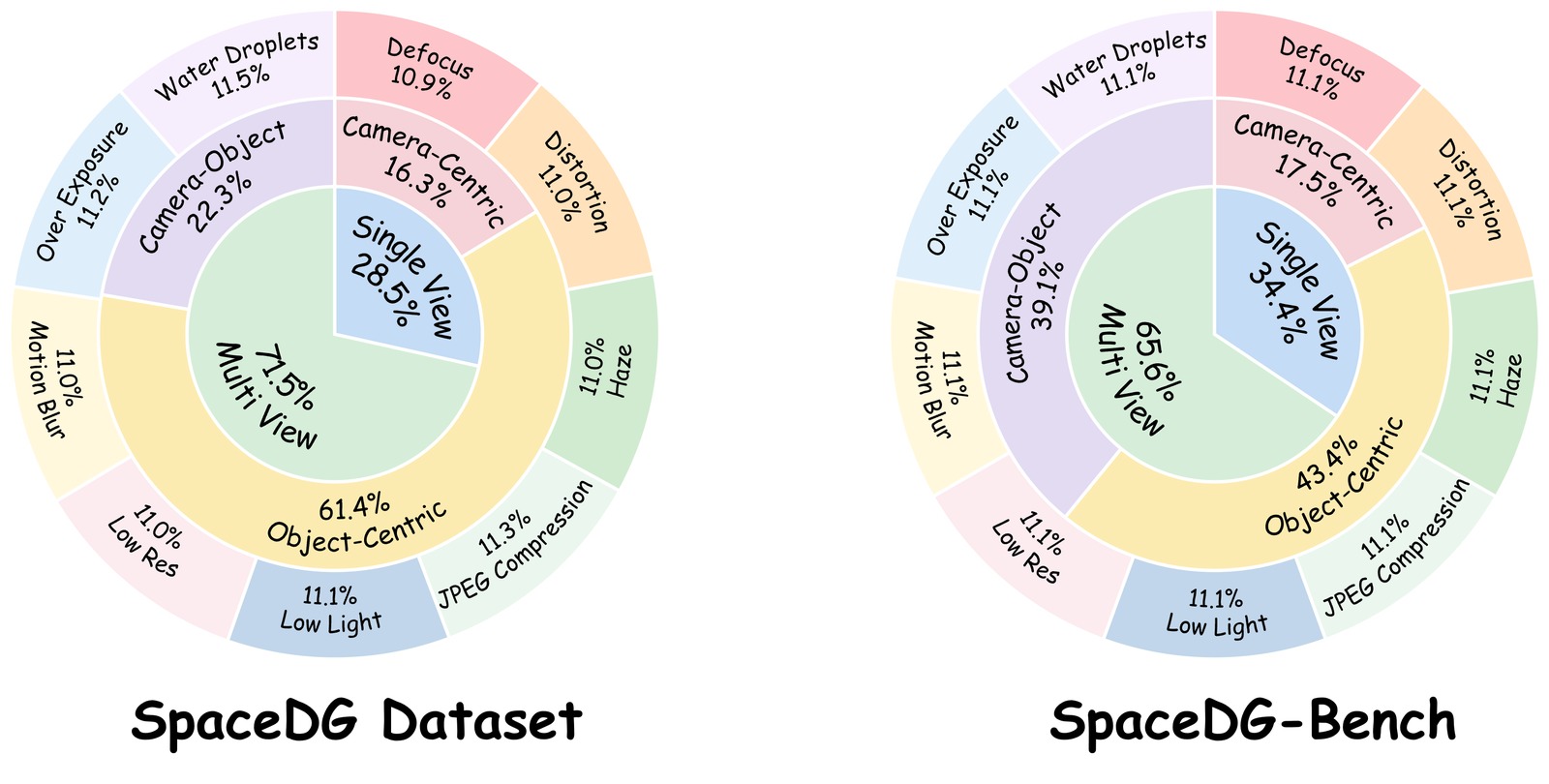
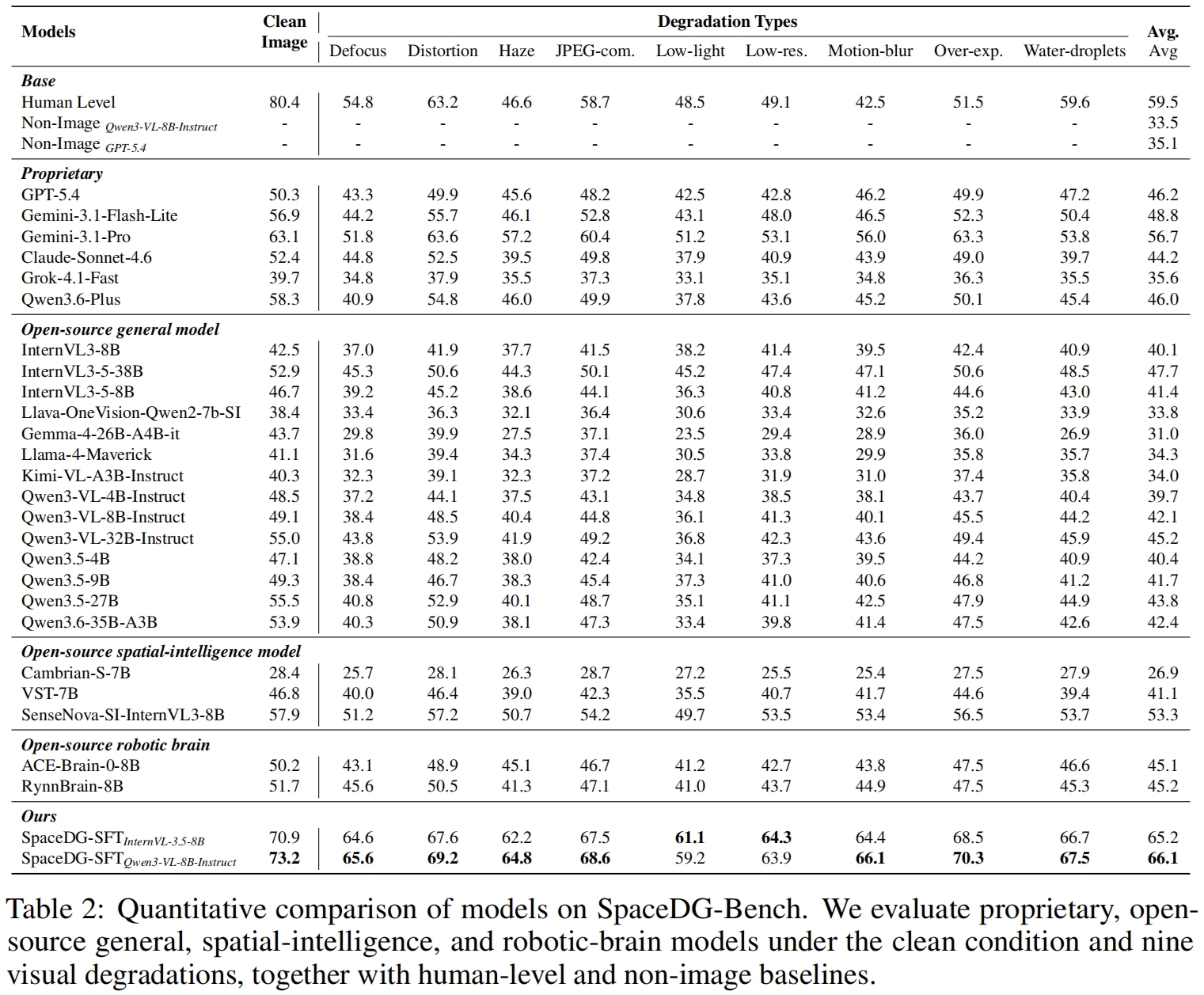
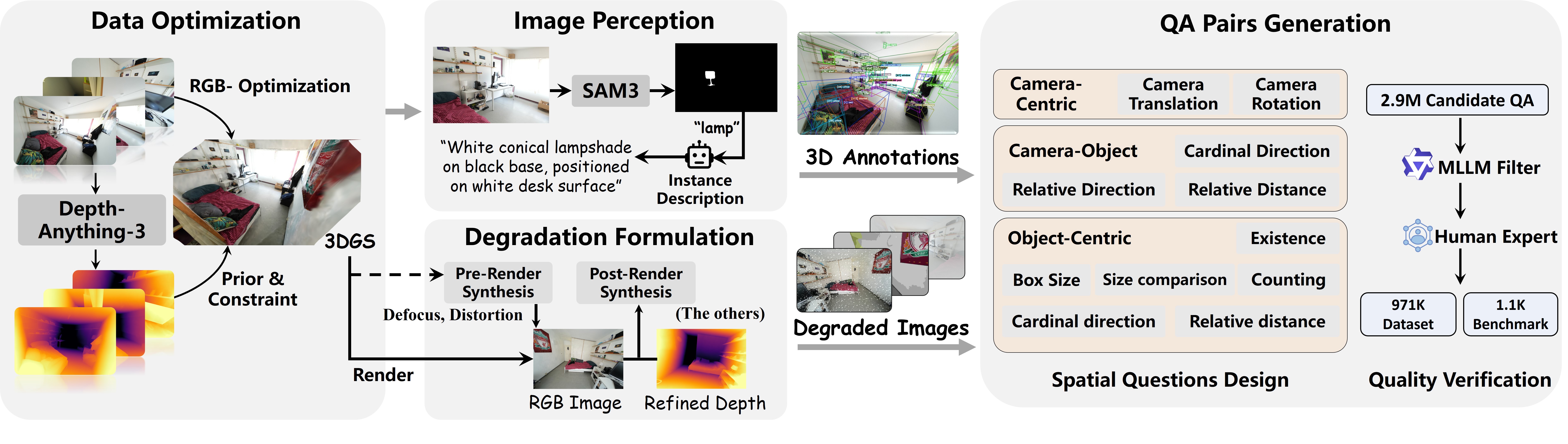
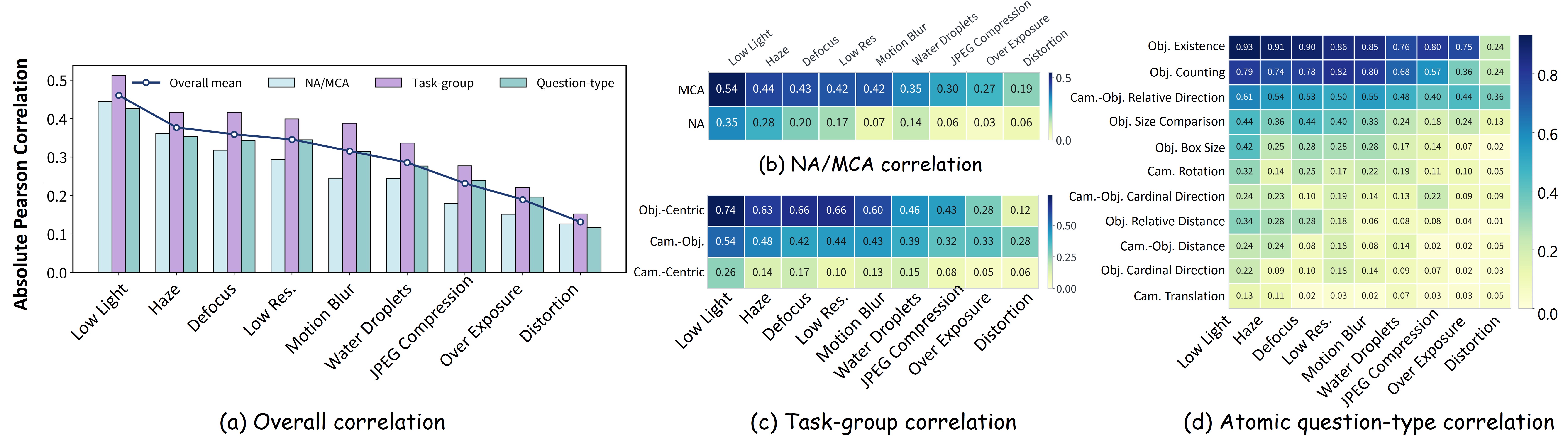
Multimodal Large Language Models (MLLMs) have made rapid progress in spatial intelligence, yet existing spatial reasoning benchmarks largely assume pristine visual inputs and overlook the degradations that commonly occur in real-world deployment, such as motion blur, low light, adverse weather, lens distortion, and compression artifacts. This raises a fundamental question: How robust is the spatial intelligence of current MLLMs when visual observations are imperfect? To answer this question, we introduce SpaceDG, the first large-scale dataset for degradation-aware spatial understanding. It is constructed with a physically grounded degradation synthesis engine that embeds degradation formation process into 3D Gaussian Splatting (3DGS) rendering, enabling realistic simulation of nine degradation types. The resulting dataset contains approximately 1M QA pairs with over 160K images. We further introduce SpaceDG-Bench, an human-verified benchmark with 1,102 unique questions spanning 11 question types and 9 visual degradation types, yielding 10K VQA instances. Evaluating 25 open- and closed-source MLLMs reveals that visual degradations consistently and substantially impair spatial reasoning, exposing a critical robustness gap. Finally, we show that finetuning on SpaceDG markedly improves degradation robustness and can even surpass human performance under degraded conditions without any performance drop on clean images, highlighting the promise of degradation-aware training for robust spatial intelligence.